


建立的机器学习模型有可能是错误的四种原因
机器学习模型很多,例如可以使用线性回归进行数值预测,使用logistic回归进行目标分类,或者使用神经网络建立描述非线性行为的预测模型。当建立这些模型时,我们通常是使用一组历史数据以帮助我们的机器学习算法学习一组输入特征和预测输出之间的关系。但是,即使这个模型可以准确地预测出历史数据的值,我们怎么知道它对新的数据也能进行准确预测呢?
更确切地说,我们如何评估机器学习模型实际上是“好”的?
在这篇文章中,我们将探讨如何通过偏差(Bias)、方差(Variance)、精确率(Precision)、召回率(Recall)这四个指标评估一些看似良好的机器学习模型仍然可能是错误的,并提出了一些解决方案。
高偏差或高方差(High Bias or High Variance)
在评估一个机器学习模型时,首先要评估的是这个模型是否有“高偏差”或“高方差”。
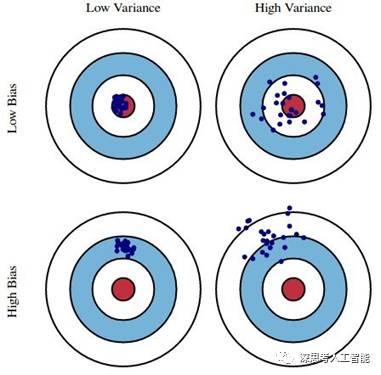
偏差度量了机器学习模型的期望预测与真实结果的偏离程度,即刻画了机器学习模型本身的拟合能力。高偏差反映出了机器学习模型对训练数据集具有较大的偏离或欠拟合(underfitting)。如上图,蓝点代表机器学习模型的预测值(输出值),红心代表实际值,高偏差就意味着蓝点距离红心比较远,即模型的预测值和实际值之间的差异较大。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。高方差反映出机器学习模型对训练数据集具有较好的拟合或过拟合(overfitting),容易受训练数据的影响。如上图,蓝点分布比较分散,这样的机器学习模型对训练数据预测有效,但对于未知数据(红心)预测能力不强,即泛化能力不强。
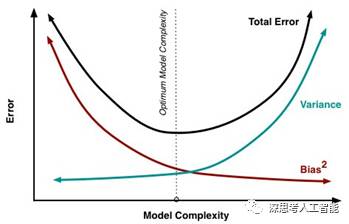
一般说来,偏差和方差是有冲突的,这被称为偏差-方差困境(Bias-Variance dilemma)。如上图所示,当机器学习模型复杂度不高(或训练不足)的时候,机器学习模型的数据拟合能力不够强,对训练数据依赖性不强,训练数据的扰动不足以使机器学习模型发生显著变化,此时偏差主导了机器学习模型的总的泛化误差。随着机器学习模型复杂度的增加,机器学习模型的数据拟合能力逐渐增强,训练数据发生的扰动逐渐能被机器学习模型学习到了,方差逐渐主导了机器学习模型的总的泛化误差。因此为了降低机器学习模型的总的泛化误差,一方面需要降低偏差,使得机器学习模型能够充分拟合训练数据,另一方面还要降低方差,使得机器学习模型对训练数据的扰动不会太多敏感。也就是说,根据训练数据建立的机器学习模型既要对训练数据学习得好,但又不能学习得太好,这就是偏差-方差困境。
但是如何知道所建立的机器学习模型有高偏差或高方差呢?
一个简单的方法是将原始数据划分为训练集和测试集。例如,使用原有数据集中70%的数据来训练模型,然后使用余下的30%的数据来进行测试。如果所建立的机器学习模型在训练集和测试集上都有很高的错误率,这就说明机器学习模型在训练集和测试集上都欠拟合(underfitting),具有高偏差。如果所建立的机器学习模型在训练集中错误率不高,但在测试集中有很高的错误率,这说明机器学习模型在训练集上过拟合(overfitting),具有高方差,所建立的机器学习模型泛化能力不强。
如果可以在训练(过去)和测试(未来)数据集中生成一个整体错误率很低的机器学习模型,这将会是一个“恰到好处”的模型,平衡偏差和方差在一个恰当的水平。
低精确率或低召回率(Low Precision or Low Recall)
即使建立的机器学习模型具有很高的预测准确率,该机器学习模型也有可能会受到其他类型错误的影响。
例如在电子邮件分类的应用中,邮件可以分为垃圾邮件(正类)和非垃圾邮件(负类)。在99%的情况下,收到的邮件不是垃圾邮件,但也许有1%的情况下是垃圾邮件。如果训练建立的机器学习模型始终预测电子邮件不是垃圾邮件(负类),那么它的预测准确率将是99%,预测准确率非常高。但这样的模型对垃圾邮件(正类)并没有预测能力,而电子邮件分类的情况下我们更关注对垃圾邮件(正类)的预测能力。
针对这类问题,实际场景中我们通常使用精确率和召回率这两个指标来对机器学习模型的预测能力进行评估。
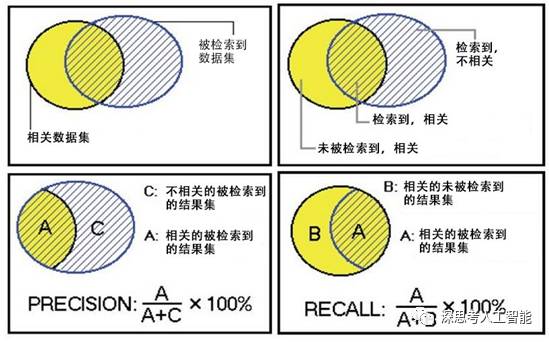
精确率(有时也被称为查准率)是用来衡量机器学习模型对正类的预测准确率的指标。如上图所示,精确率等于真正检索到的垃圾邮件结果集(即预测电子邮件是垃圾邮件,它实际上也是垃圾邮件),除以所有检索被认为是垃圾邮件结果集,其中包括真正的垃圾邮件和误报(即预测电子邮件是垃圾邮件,但实际上它并不是)。
召回率(有时也被称为查全率)是用来衡量机器学习模型对正类的预测准确率的另一个指标。召回率等于真正检索到的垃圾邮件结果集(即预测电子邮件是垃圾邮件,它实际上也是垃圾邮件),除以所有真正的垃圾邮件结果集,其中包括真正的垃圾邮件和漏报(即预测电子邮件不是垃圾邮件,但实际上它是)。
可以从另一个角度来解释精确率和召回率之间的差异。精确率是衡量机器学习模型的预测结果中对正类的预测有多大可能性是正确的,而召回率是衡量机器学习模型对正类有多大可能性进行正确预测。因此,如果建立的机器学习模型精确率比较低,说明在该模型的预测结果中对正类的预测准确率很低,如果建立的机器学习模型召回率比较低,说明该模型对正类缺少预测能力,无法对正类进行准确预测。
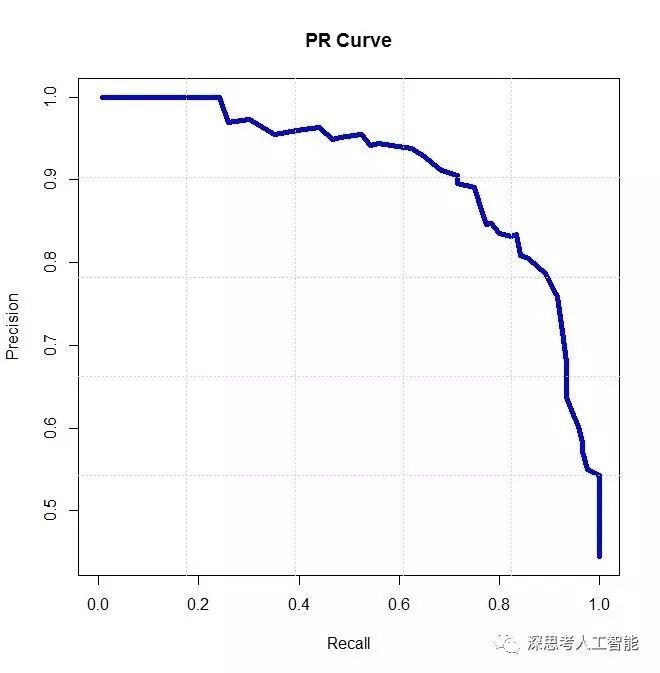
与偏差和方差的关系类似,精确率和召回率也是一对矛盾的度量(如上图)。一般说来,精确率高时,召回率往往偏低;而召回率高时,精确率往往偏低。良好的机器学习模型的目标之一就是在精确率和召回率之间获得一个平衡,一方面最大限度地提高对正类样本的预测准确率,另一方面尽量减少假阴性和误报的数量。
提高机器学习模型泛化能力的五种方法
如果建立的机器学习模型中存在高偏差和高方差的问题,或者在精确性和召回率之间有问题,可以采用下面一些策略提高模型的泛化能力。
对于机器学习模型具有高偏差的情况,可以尝试增加学习样本的输入特征。如前面所述,高偏差的出现是因为机器学习模型对数据欠拟合(underfitting)造成的,这造成了机器学习模型在训练集和测试集上的错误率比较高。通过构建模型错误率和输入特征之间的映射函数,可以发现随着学习样本的输入特征增加,模型的高偏差问题可以得到校正。
在相反的高方差情况下,可以尝试减少学习样本的输入特征。如果机器学习模型过度拟合训练数据(overfitting),很可能是因为使用了太多的输入特征,减少输入特征的数量会使机器学习模型对测试或未来的数据集更有泛化能力。同样,增加学习样本的数量也可以帮助解决高方差问题,更多的学习样本可以帮助机器学习算法建立一个更具有泛化能力的模型。
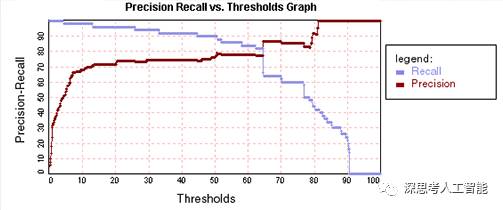
为了解决低精确率和低召回率的情况,可以设定一个阈值(threshold)来对机器学习模型的学习能力进行评估调整。如上图,在低精确率的情况下,可以增加阈值,使得机器学习模型更偏保守,对正类具有更高的预测准确率。另一方面,对于低召回率的情况,可以降低阈值,使得机器学习模型更侧重去预测正类样本。只要保证有足够的迭代,最终总是可以找到一个适当的机器学习模型,达到偏差和方差、精确率和召回率之间的平衡。




